
Genetics 101
Immortal Coils
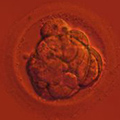
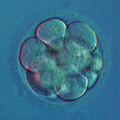
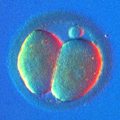
The building block of every living organism on Earth is the cell. Whether it is a single bacteria or a congregation of billions of cells in the shape of an elephant or a giant sequoia, a single cell is how we all start and what we, living beings, are made of. Cells are microscopically small; thousands of cells may dance on the head of a pin!
Like humans, each cell has a "spark of life" inside, it is a long polymer molecule called Deoxyribonucleic Acid (DNA). DNA contains the information about the cell itself, on how to divide and make more cells, on how to differentiate and build the organs these cells form, information about the organism these organs serve, and finally the instructions (called instincts) on how these living creatures go about living their lives. It is a lot of information, information of vital importance! It should be stressed here that the only function of DNA is to store information, nothing more. All the dirty work of actually doing something, including synthesis of the DNA itself, or DNA replication, is done by the proteins and RNA.
Human DNA, if stretched out in a line, is almost four feet long and contains enough information to be compared to the Library of Congress or the Encyclopædia Britannica (depending on which side of the Pond you are on), or to gigabits of data, for those young enough not to care about printed pages. This enormously long strand of DNA fits inside a tiny cell by coiling, supercoiling and folding itself into more manageable lengths. Eukaryotic DNA shortens itself by winding around the special proteins called histones, then by compacting into the so-called 30nm chromatin fiber, then by supercoiling into a left-handed super-helix.
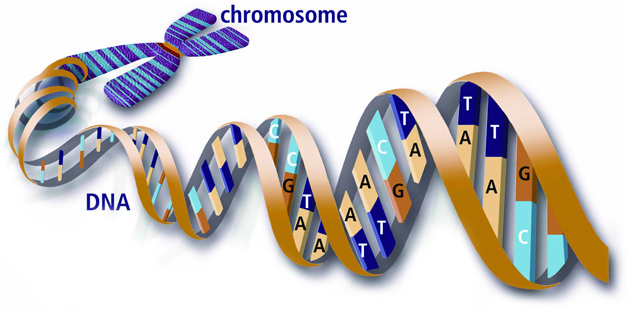
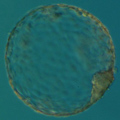
However, this level of compaction is still not compact enough to be manageable during cell division, so the strand of human DNA is actually broken into 23 pieces. Each of these pieces is called a chromosome and is visible as a separate entity only during cell division (called mitosis) when DNA undergoes its highest levels of compaction. In its normal, non-dividing state (called interphase) each cell keeps and protects its DNA inside the cell nucleus, visible under the microscope as a transparent almost homogenous structure packed with DNA.
To be an enormously long but at the same time an extremely stable molecule is a remarkable feat, however, this is not the reason why DNA is considered the most amazing molecule on Earth. After all, polyethylene and cellulose are also long polymers comprised of ethylene or sugars. It is the ability to store and faithfully multiply information that makes DNA so special. If we look at the building blocks of this huge molecule, we shall see that the backbone of DNA is a molecule of deoxyribose (sugar). Billions of these interconnected (polymerized) molecules form the backbone of DNA. Left to itself, this would be just another type of cellulose, but each molecule of deoxyribose, apart from being attached to other deoxyriboses, is also connected to one out of four purine/pyrimidine bases, best known by their initials: A, T, G, C. These so-called nucleotides are the letters of the genetic code through which DNA (hopefully by now its full name, deoxyribonucleic acid is more manageable) codes the almost-infinite amount of information necessary for the building of a living creature.
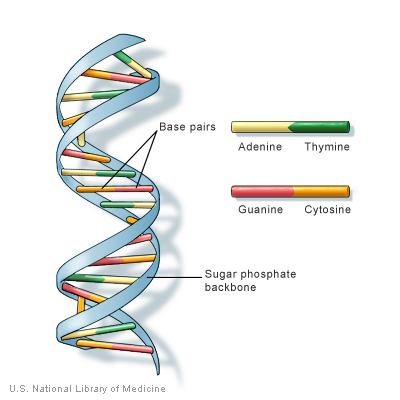
(DNA is not one, but actually two polynucleotide strands. In physical terms this means that each polynucleotide strand lies next to another polynucleotide strand, and these strands are interconnected. A of each strand (so-called "sense" strand) is always connected to T from the opposite strand (called "antisense strand"), and G is interconnected with C into base pairs. This is why DNA is also called a "double helix": it consists of two interconnected polynucleotide strands running parallel to each other and also shaped like a spiral.)
Now that the DNA's physical structure and the letters of the genome's alphabet are revealed, it is time to introduce the concept of gene. We shall use the terminology of molecular biologists by saying that gene is a stretch of DNA coding information about a specific protein.
The nucleotide sequence ATGGATGCACACAAG ... TAA is as clear to any cell as the following message to us: START protein synthesis, grab amino acid Asparagine, link to amino acid Alanine, link to amino acid Histidine, link to amino acid Lysine ... STOP protein synthesis. Another molecule of human albumin is synthesized!
Humans have approximately 25,000 genes in their DNA, which takes up less than 10% of the genome. The other 90+% consist of broken/discarded genes (pseudogenes), viral genomes successfully inserted into the DNA of our ancestors before being neutralized, satellite DNA at chromosome centromeric regions, telomeric DNA, transposons and selfish DNA, and huge stretches of DNA for which we have no names and no plausible explanation.
Genetic Defects
Single-Gene Mutations
There is an infinite number of ways how the information stored in DNA may become corrupted. It may come at the level of an individual gene if, say, the first nucleotide A in the sequence above becomes substituted for G and albumin synthesis fails to start, or the sixth nucleotide T becomes substituted for G and instead of Asparagine, Glutamine becomes the first amino acid in the chain. Sometimes small variations in protein composition are acceptable, sometimes (in case of antibodies) desirable, and in other instances (histone H4) instantly lethal.
Over 10,000 human diseases are caused by defects in single genes. Single gene disorders, which are also described as monogenic diseases, and sometimes as mutations, are individually very rare but geneticists estimate that each of us carries about a dozen lethal genes in our DNA. It is only due to the fact that each of us has TWO full copies of human genome in each and every cell, that lethal genes cannot reveal themselves. Having at least one Normal copy of a gene (called wild-type allele) is usually enough to prevent the expression of a mutant gene.
Chromosomal Abnormalities
There is no smaller defect in human genome than the substitution of one nucleotide out of a few billion. On the other end of the scale are genetic disruptions of global proportions:
- Polyploid is a term used to describe cells or embryos where the whole genome was duplicated, or multiplied several times.
(As mentioned before, the whole human genome is broken into 23 pieces, called chromosomes. One set of 23 chromosomes is called a haploid set, and although it is a full set, containing the whole human genome, only mature oocytes and spermatozoa have haploid set of 23 chromosomes. Each somatic cell and each cell of the human embryo has a diploid set of chromosomes (as always, di- stands for double) thus it is correct to say that humans have 46 chromosomes, or 23 pairs of chromosomes.
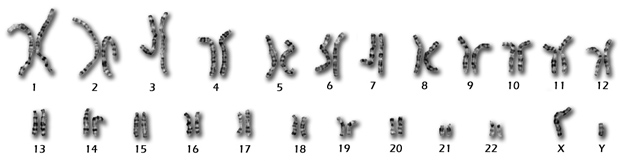
To complicate things further, there are not 23, but 24 different human chromosomes. Chromosomes 1 through 22 are known by their number and called autosomes, and chromosomes X and Y are known as the sex chromosomes. During fertilization, 23 chromosomes are inherited from the mother and the other 23 chromosomes arrive tightly packed inside the father's spermatozoon. As a result, a normal male human embryo will have 46 chromosomes: 44 autosomes (or 22 pairs of homologous chromosomes), one X plus one Y chromosome. A normal female embryo will have 44 autosomes and two X chromosomes. In other words, although it is traditional and quite correct to say something like "my genome", the fact remains that "your genome" is actually two full human genomes!)
The lower level of pangenomic disasters, right after whole genome amplification, would be the addition of a whole chromosome:
- Aneuploidy is the term for the cases when an embryo (or a cancer cell) has too many or too few chromosomes, compared to the normal set of 46 chromosomes. Down's Syndrome, or trisomy of chromosome 21, is the best known, and the most feared case of aneuploidy in humans.
At even lower levels of chromosomal aberrations we shall see the changes in chromosome structure:
- Translocations occur when a piece of one chromosome becomes attached to another chromosome. Reciprocal translocation means that two chromosomes swapped their segments. Robertsonian translocation means that two acrocentric chromosomes fused to form one chromosome.
- Deletion means that a segment of a chromosome is missing.
- Inversion means that a segment of chromosome is inverted without changing its original location.